-
-
Manipulator Demo: Smooth action chunck sequence generation with predictive flow matching denoising decoder for VLA
Read more ⟶Introduction
VLA (Vision-Language-Action) models have shown promising results for robots to perform tasks in complex environments based on visual input and textual instructions. Specifically, chunk-based action generation is crucial for its long-horizon planning and short-term per-chunk smooth motion. However, naive chunk-by-chunk action execution strategy may result in jerky robot motion when switching chunks. In this blog, a predictive flow-matching-based action decoder design is proposed to generate smooth action sequences, which forms a key component of our lightweight VLA variant implementation.
…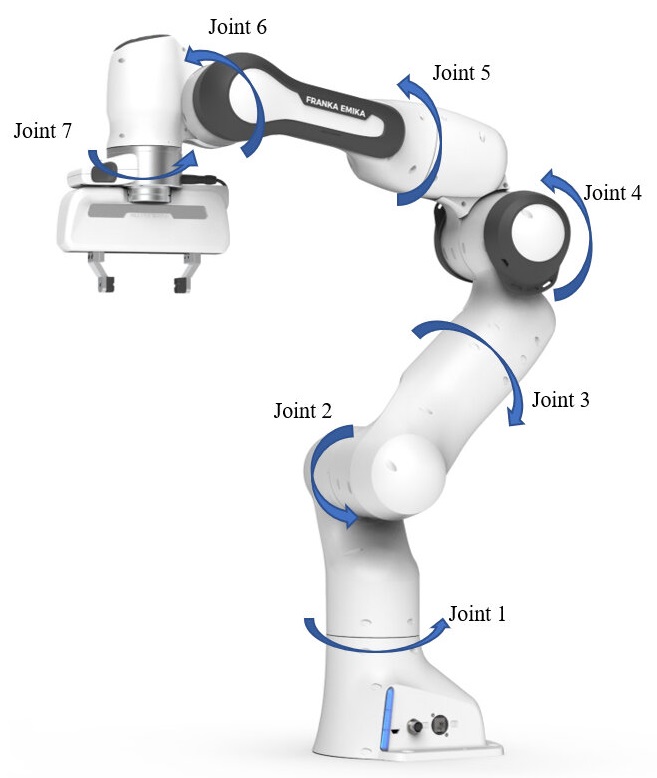
Franka Panda Emika Robot
(RoboGroove©)Task: turn on the stove and put the moka pot on it
-
-
Humanoid Demo: Game2D-to-Sim3D Cross Domain Skill Adaptation From CPG Expert Demonstrations
Read more ⟶Introduction
In previous blog posts, we have shown successful applications of CPG-based RL for robot locomotion in both 2D (game) and 3D (world) physical simulation environments. While this approach offers the flexibility to adjust parameters for walking gait on-the-fly, it necessitates heavy reward tuning and prolonged training time. On the other hand, imitation learning from human demonstrations has shown more rapid convergence for natural gait cloning. Here we will try to combine these two techniques and explore the feasibility of using a 2D CPG expert to guide a 3D humanoid robot in learning to walk.
…