Entries tagged :: Manipulator.
-
Manipulator Demo: Smooth action chunck sequence generation with predictive flow matching denoising decoder for VLA
Read more ⟶Introduction
VLA (Vision-Language-Action) models have shown promising results for robots to perform tasks in complex environments based on visual input and textual instructions. Specifically, chunk-based action generation is crucial for its long-horizon planning and short-term per-chunk smooth motion. However, naive chunk-by-chunk action execution strategy may result in jerky robot motion when switching chunks. In this blog, a predictive flow-matching-based action decoder design is proposed to generate smooth action sequences, which forms a key component of our lightweight VLA variant implementation.
…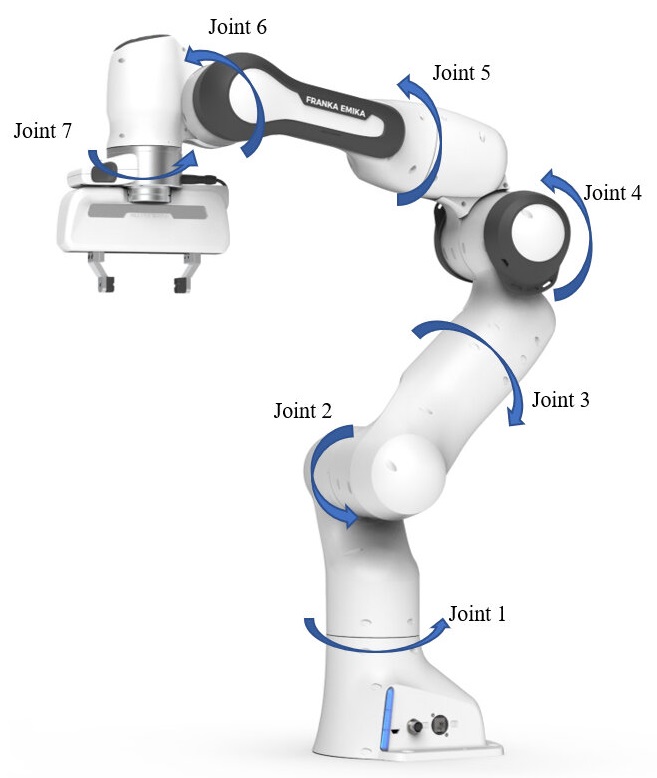
Franka Panda Emika Robot
(RoboGroove©)Task: turn on the stove and put the moka pot on it